刚刚学了PyTorch,写个神经网络试试…
给定泰坦尼克号上名乘客的信息: 姓名、性别、年龄、船票等级、家属等,以及这些乘客是否存活。目标是判断另外名乘客是否存活。
使用PyTorch训练一个神经网络来完成这个任务。
数据预处理
首先描述一下数据预处理的过程。
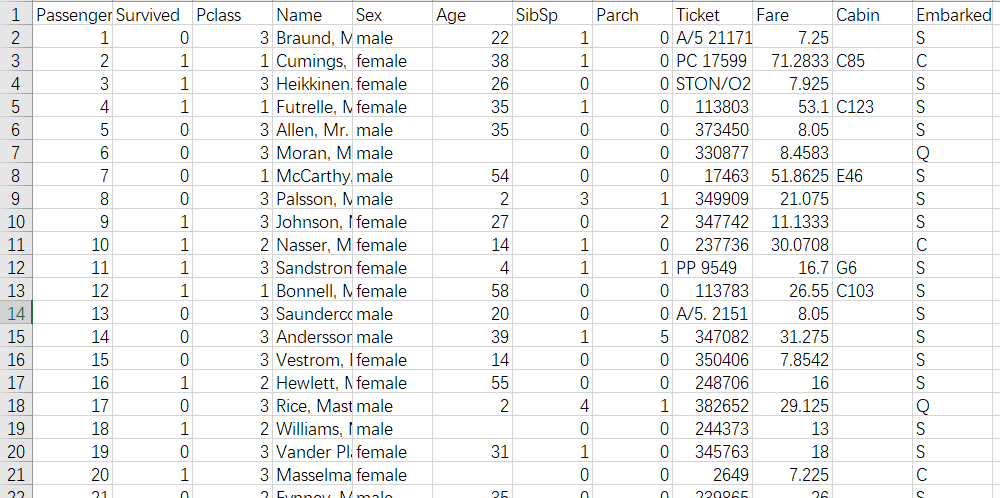
观察一下,主观臆断初步分析和感觉可以得出: 乘客编号(PassengerId)应该是完全没用的信息;姓名(Name)似乎和存活关系也不大;船票号(Ticket)由于数据太杂乱了,有用,但是应该会很麻烦;如果知道泰坦尼克号每个隔间的位置以及逃生通道的位置,隔间号(Cabin)应该是非常重要的信息,然而数据缺失特别严重,这意味着将其作为重要标准会有问题。
因此只利用其他数据: 船票等级(Pclass), 姓名(Name), 性别(Sex), 年龄(Age), 登船兄弟个数(SibSp), 登船长辈个数(Parch), 票价(Fare), 登船港口(Embarked)。还需要对这些数据进行预处理。
补足Age数据
看一眼就可以发现在Excel中筛选或用pandas的isnull()函数检查发现,训练集和测试集年龄数据都存在大量缺失。存在大规模数据缺失问题,一般可以采取的方法有: 均值填补、中位数填补、众数填补、矩阵分解补全、随机森林、预设未知项等等。尝试发现均值和中位数填补方法效果不好,票价很多导致众数在这道题中不够明显,矩阵分解补全和随机森林又比较复杂(不过可以引用一些写好的库),因此采用预设未知项。补充UknAge属性表示不知道年龄,对于Age缺失的数据将此项设置为。(感性理解可以认为将来神经网络会利用UknAge的权重来动态为缺失项填补一个估计值)。
(网上的随机森林做法我感到非常疑惑,如果说兄弟个数和长辈个数还勉强可以反映年龄(即使这里只记录了登船的亲属个数),那为什么年龄和性别会有关联?用性别参与预测年龄有什么依据?)
补足Embarked数据
某次运行Python程序得到少量NaN输出结果于是发现在Excel中筛选或用pandas的isnull()函数检查发现,训练集登船港口数据有2人缺失。登船港口应该会和什么有关呢?个人感觉登船港口不同可能导致里程不同,从而影响票价,发现缺失数据的人票价都为。同时为了控制变量,性别、船票等级都会影响票价,因此筛选所有票价在之间的男性头等舱船票。
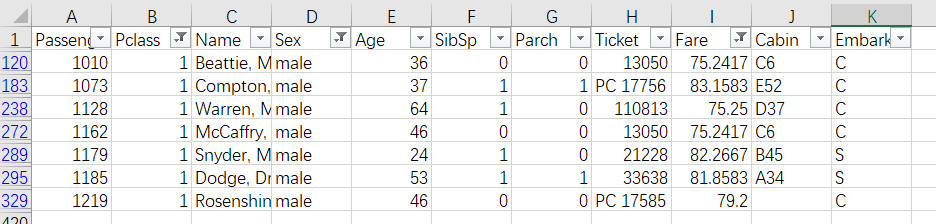
发现大多数来自于C港口。因此可以假定缺失数据的人从C港口登陆。
补足Fare数据
再次运行Python程序得到少量NaN输出结果于是发现在Excel中筛选或用pandas的isnull()函数检查发现,测试集有人票价数据缺失。

根据此前对票价影响因素的分析,用相同登船港口、船票等级、性别的乘客取中位数来作为预测票价(均值明显偏高)。得出。
数据离散化(One-hot Encoding)
为了方便神经网络处理,应该将离散数据都拆成多项。例如将登船港口拆分为个属性,“是否从C港口登船”,“是否从Q港口登船”,“是否从S港口登船”,每个属性都是二值。因此经过离散化,最终得到了个不同的属性(加上是否存活的label一共个属性):
1 | NEW_INDEX = ['Age', 'UknAge', 'Fare', |
数据归一化(Normalization)
为了方便神经网络处理,将所有数值转化为介于之间的数值。~~叒运行Python程序全部得到NaN输出结果于是注意到,~~不能直接全部除以最大值,而需要判断最大值是否非(刚刚用填充NaN的列最大值可能为)。
代码实现
最开始直接裸写…那叫一个痛苦,代码又臭又长…对于压行教信徒的我简直是奇耻大辱
于是去学了numpy和pandas入门…重构了无数次代码以后变成了下面勉强可以接受的样子…
1 | # Configurations |
PyTorch构建全连接深度神经网络
本来的目的就是初学PyTorch,写个神经网络测试一下,才误打误撞找到了Kaggle这个比赛。直接通过nn.Sequential()和add_module()构建一个可以自由调参数的神经网络模板。激活函数都可以从若干中随意设定(为了方便选择以及输出参数采用了字典形式)。
注意nn.Softmax()是个坑人函数,其是针对多维设计的,必须要传入axis=?表示对第几维度求Softmax,因此一维Softmax应该为nn.Softmax(0)。
训练集总共个数据,实际训练时将个数据设定为真·训练集,其余个数据为验证集。
1 | ACTIVATION = {'sigmoid':nn.Sigmoid(), |
具体运行流程经历了多个版本。最开始是手动瞎猜调节神经网络的各个参数,后来开始手动编写网格式搜索参数,但是由于速度实在过慢令人难以忍受,于是随机化。
如此生成一个随机的全连接深度神经网络:
1 | ACTIVATION = {'sigmoid':nn.Sigmoid(), |
每一层神经网络节点数都是2的整倍数,介于之间。初始学习率为之间的小数,然后以的速度进行衰减(手动构造+检验表明,当介于之间时,这样一个衰减速率可以使得最终学习率保持在一个合理区间内)。由于训练集数据量比较小,batch_size也比较小,直接取了测试集大小的部分小约数。后来也尝试了直接固定学习率。
运行起来大约是这个样子:
1 | [FCDNN(26-32-2-64-2,softplus) 3000*160*5] with optimizer [<class 'torch.optim.adam.Adam'>]: |
集成(Ensemble)
集成就是对若干个不同参数的神经网络进行综合。~~要平等不要平均,~~对每个神经网络按照其在验证集上的表现进行加权,具体地,考虑错误率:
具体实现对于神经网络自身,定义评估权重的函数:
1 | class FCDNN( nn.Module ): |
因为某些优化器表现似乎不太稳定,于是添加了特殊限制: 验证集错误率超过的网络的输出方案将被直接作废。
最终运行(其实一次划分真·测试集和验证集足够,激进冒险主义者为了引入更多随机性,每个网络重新划分):
1 | def output( prediction, filedir ): |
完整代码
1 | import torch |
注: 采用了固定学习率;验证集错误率限制改为;注意PATH未定义。Kaggle Kernel版本。
效果
泰坦尼克数据集令人尴尬的一点在于,由于"妇女和儿童先走",直接判断性别女为存活性别男为不存活就可以实现的正确率。同时由于来自于真实的历史事件,数据是公开的,因此"可以实现"正确率。
目前实现的最优解为,在Top 的水平(作为Kaggle入门比赛,榜单每三个月会清零一次),很可惜的是没能记录下参数。另外一个事实是,这一最优解是在没有Ensemble的情况下做到的(某次运行中第一个训练完成的神经网络)。

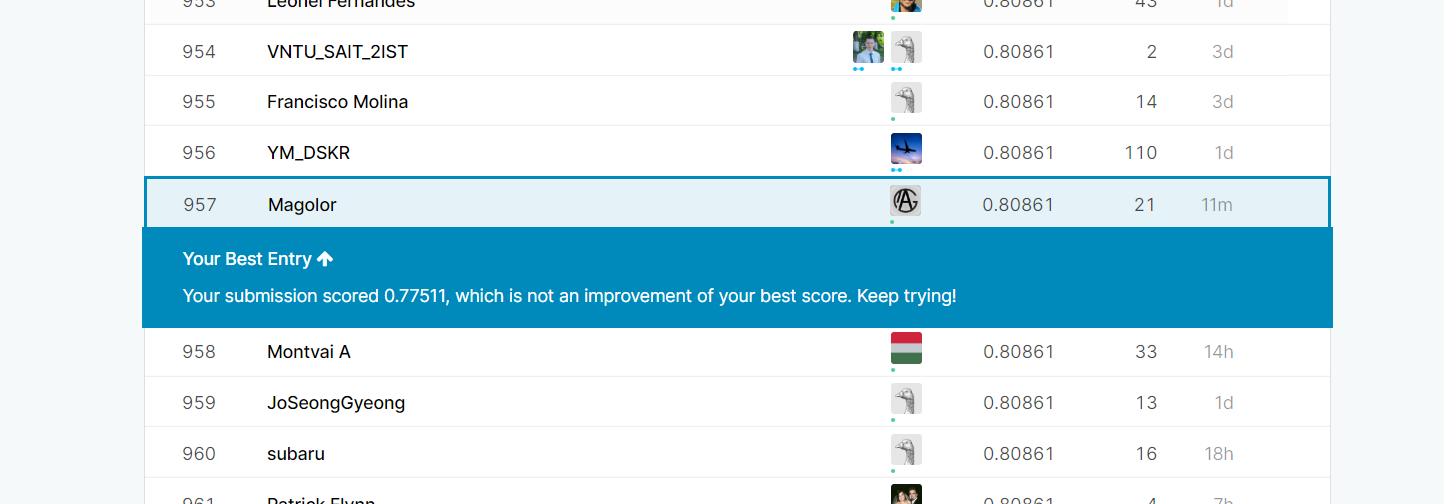
评论区中也有人猜测左右是最高的正确率,鉴于训练集过小,更高的模型都可能存在潜在的过拟合。
扫描二维码即可在手机上查看这篇文章,或者转发二维码来分享这篇文章:

